프론티어 모델 출시의 첫 관문이 벤치마크가 아니라 워싱턴이 됐다
한 주 사이에 두 번째다. Anthropic의 Fable 5가 수출통제를 거쳐 돌아온 바로 그 주에, OpenAI는 차세대 모델 GPT-5.6을 발표하면서 일반 공개 대신 “미국 정부의 요청에 따라” 소수 파트너에게만 여는 길을 택했다. 신모델 발표에서 우리가 늘 먼저 보던 것 — 벤치마크 점수, 데모 영상 — 보다 앞에, 이번엔 정부 협의라는 절차가 있었다.
무슨 일이 있었나
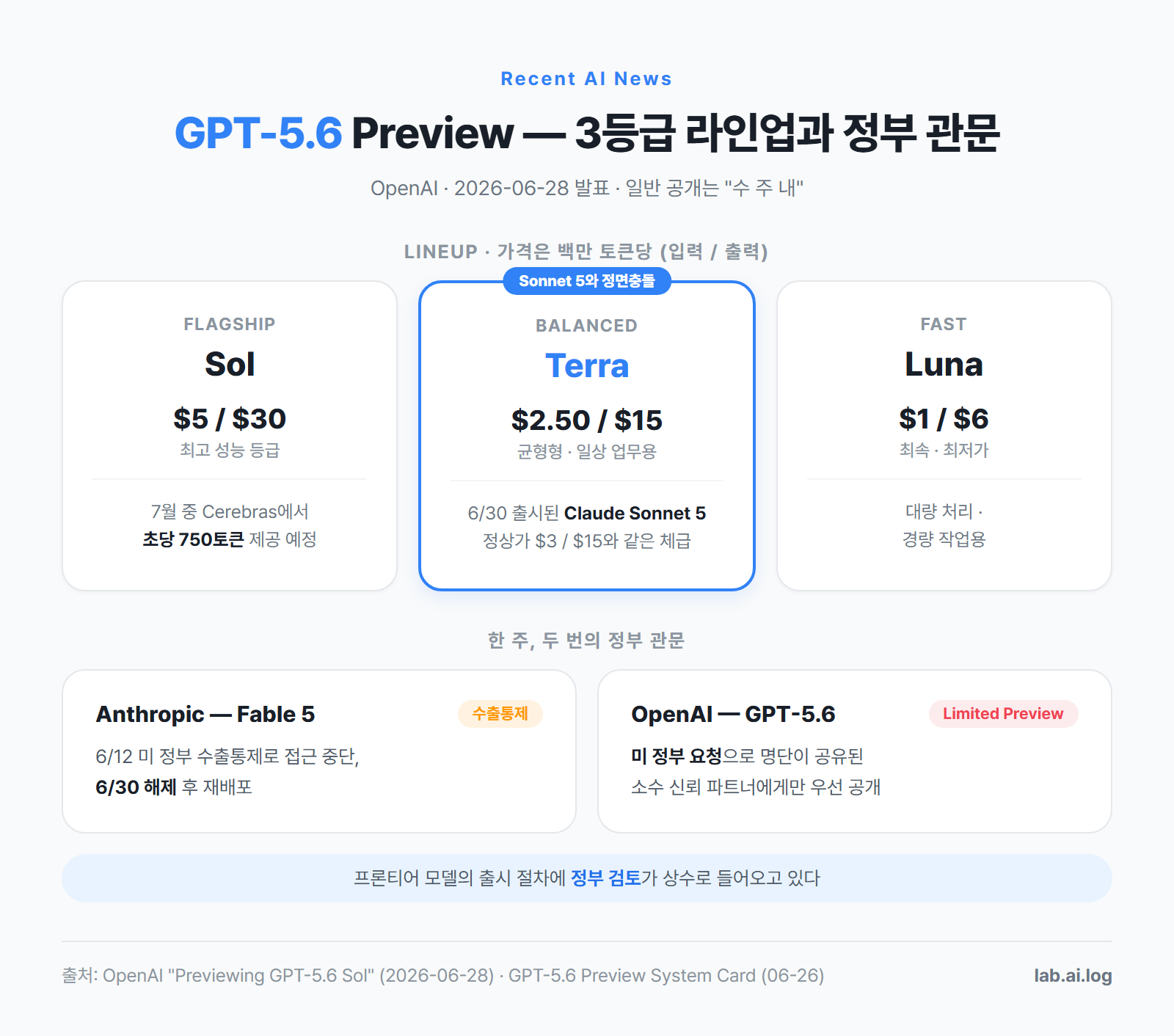
OpenAI가 6월 28일 GPT-5.6 패밀리를 발표했다(안전 평가를 담은 system card는 6월 26일에 먼저 게시됐다).
라인업은 세 등급이다. 플래그십 Sol, 균형형 Terra, 최속·최저가 Luna. 가격은 백만 토큰당 Sol $5/$30, Terra $2.50/$15, Luna $1/$6 (입력/출력). 익숙한 구조다 — Anthropic의 Opus·Sonnet·Haiku와 같은 3단 구성이고, 심지어 균형 등급의 가격대까지 겹친다. 이틀 뒤 나온 Claude Sonnet 5의 정상가가 $3/$15다.
공개 방식이 이번 발표의 진짜 뉴스다. system card에 따르면 OpenAI는 “미국 정부와의 지속적 협의의 일환으로” 출시 전에 계획과 모델 능력을 공유했고, “정부의 요청에 따라” 참여 명단이 정부와 공유된 소수 신뢰 파트너에게만 limited preview를 열었다. 외신 보도로는 약 20개 기관이고 명단은 비공개다. ChatGPT·Codex·API를 통한 일반 공개는 “수 주 내”라고만 밝혔다.
왜 정부가 끼어드는가. system card의 안전 평가를 보면 감이 온다. 세 모델 모두 사이버보안과 생물·화학 영역에서 “High” 등급 — OpenAI의 위험 분류에서 실질적 피해 가능성을 따져야 하는 수준 — 을 받았다. 동시에 한계도 명시됐다. Sol과 Terra는 소프트웨어 취약점을 찾아낼 수는 있지만, 방어가 강화된 시스템에 대한 자율적인 전 과정 공격(end-to-end attack)에는 실패했다. 이런 능력 평가가 정부와 사전 공유되는 것, 그 결과에 따라 공개 범위가 조정되는 것 — 이게 이번에 확인된 새 절차다.
개발자용 변화 중 제일 실속 있는 것은 prompt caching 개선이다. prompt caching은 반복 사용하는 컨텍스트(시스템 프롬프트, 참고 문서 등)를 서버에 캐시해 두고 재사용할 때 할인해 주는 기능이다. 이번에 캐시를 어디서 끊을지 지정하는 명시적 breakpoint와 최소 30분의 캐시 수명이 들어왔다. 캐시 쓰기는 입력 단가의 1.25배, 읽기는 90% 할인. 지금까지 캐시가 언제 사라질지 예측하기 어려워 설계가 곤란했는데, 30분 보장은 에이전트 설계의 계산을 바꾼다.
추론 속도도 한 단계 올라간다. 플래그십 Sol이 7월 중 Cerebras — 웨이퍼 한 장을 통째로 칩으로 쓰는 추론 전용 하드웨어 회사 — 에서 최대 초당 750토큰으로 제공될 예정이다(초기 일부 고객). 일반적인 GPU 서빙보다 몇 배 빠른 속도로, 프론티어급 모델의 응답 대기가 사실상 사라지는 수준이다.
왜 중요한가
정부 검토가 출시 절차의 상수가 됐다. 6월 한 달 동안 Anthropic은 수출통제로 모델을 내렸다 올렸고, OpenAI는 정부 요청으로 공개 범위를 좁혔다. 서로 다른 회사가 서로 다른 형태로, 같은 관문을 통과했다. 사용자 입장에서 생기는 새 변수는 이것이다 — “기술적으로 완성된 모델”과 “내가 쓸 수 있는 모델” 사이의 시차. 발표를 봤다고 바로 쓸 수 있는 시대가 아니게 됐다.
두 회사의 라인업이 같은 모양으로 수렴한다. 플래그십–균형–경량 3등급, 겹치는 가격대. 이게 의미하는 것은 모델 선택이 점점 “어느 회사 팬인가”가 아니라 “이 작업에 어느 등급이 맞는가”의 문제가 된다는 것이다. 한쪽 생태계에만 익숙해지기보다, 등급 개념으로 사고하는 습관이 앞으로 더 쓸모 있어진다.
비용 최적화의 무게중심이 캐싱으로 이동한다. 모델 단가는 계속 내려가는 추세라 절대 단가 차이는 줄어든다. 반면 같은 컨텍스트를 하루에 수백 번 재사용하는 에이전트형 워크로드에서 캐시 적중률은 청구액을 몇 배 단위로 가른다. 단가표 비교보다 캐시 설계가 먼저인 시대가 오고 있다.
My Take
이번 발표에서 제일 오래 기억될 대목은 가격표가 아니라 출시 절차라고 생각한다. 프론티어 AI가 전략 자산으로 다뤄지는 시대에, “언제 출시되는가”는 이제 연구 로드맵이 아니라 규제 일정의 함수다. 새 모델 소식을 볼 때 체크할 항목이 하나 늘었다 — 발표일이 아니라 “내 손에 오는 날”을 확인하는 것.
실무 쪽 조언은 캐싱에 집중된다. prompt caching이 30분 보장 + 명시적 breakpoint로 바뀌면, 프롬프트를 짜는 방식 자체를 바꿀 수 있다. 원칙은 간단하다 — 바뀌지 않는 부분(시스템 프롬프트, 참고 문서, 예시)을 앞에, 매번 바뀌는 부분(사용자 질문)을 뒤에 배치하고, 그 경계에 breakpoint를 두는 것이다. 캐시는 앞에서부터 일치하는 만큼만 적중하기 때문이다. 이 원칙은 GPT-5.6만의 이야기가 아니라 캐싱을 지원하는 모든 모델(Claude 포함)에서 통하는, 지금 바로 적용할 수 있는 습관이다.
Sol이냐 Terra냐 같은 등급 고민은 일반 공개가 열린 뒤에 해도 늦지 않다. 그때 가장 먼저 볼 것은 벤치마크 순위가 아니라, 내 반복 워크로드에서의 실효 단가 — 즉 캐시 적중률이 반영된 청구액이다.