상반기 내내 “프론티어”는 비싼 모델의 다른 이름이었다. 6월 30일부터는 아니다.
최상위 모델을 쓰려면 지금까지 두 가지를 감수해야 했다. 높은 API 단가, 그리고 구독 플랜의 빡빡한 usage limit. 그래서 다들 “중요한 작업만 비싼 모델, 나머지는 싼 모델”로 나눠 쓰는 요령을 익혀 왔다. 6월 30일 Anthropic이 내놓은 Claude Sonnet 5는 그 구분선 자체를 흔든다.
무슨 일이 있었나
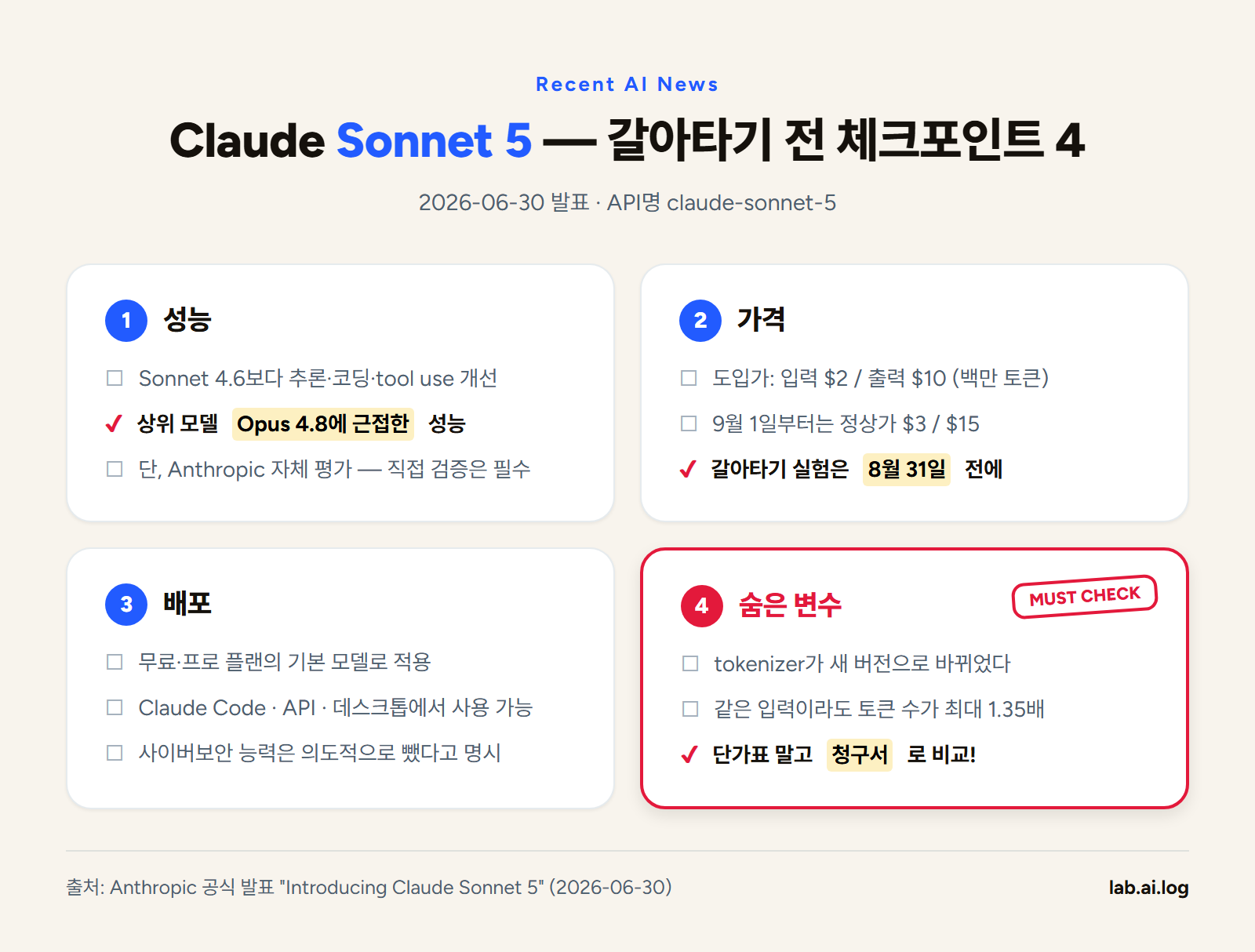
먼저 배경 하나. Anthropic의 모델 라인업은 세 등급이다 — 최상위 Opus, 주력 Sonnet, 경량 Haiku. 이 중 Sonnet이 “대부분의 사람이 실제로 쓰는” 등급이다. 이번 발표는 그 주력 등급의 세대교체다.
성능. Anthropic은 Sonnet 5가 이전 세대 Sonnet 4.6보다 추론·코딩·tool use(모델이 검색이나 코드 실행 같은 외부 도구를 스스로 다루는 능력) 전반에서 나아졌고, 자사 최상위 모델인 Opus 4.8에 거의 근접한다고 밝혔다. 어디까지나 자체 평가지만, 주력 등급에 대해 이런 표현이 나온 것 자체가 이례적이다.
가격. 오히려 내려왔다. 8월 31일까지는 도입가로 입력 $2 / 출력 $10 (백만 토큰 기준), 9월 1일부터 정상가 $3 / $15가 된다. 상위 등급에 근접한다는 모델이 중간 등급 가격표를 달고 나온 셈이다.
배포. Claude.ai 무료·프로 플랜의 기본 모델로 바로 적용됐다. 아무 설정을 안 해도 오늘 Claude를 열면 이 모델이다. Claude Code, API(claude-sonnet-5), 데스크톱 앱, Max·Team·Enterprise 플랜에서도 쓸 수 있다.
안전. hallucination(그럴듯한 거짓 정보를 지어내는 현상)이 줄었고, prompt injection — 문서나 웹페이지 안에 숨긴 지시문으로 AI를 조종하는 공격 — 에 대한 저항이 강해졌다고 한다. 특이한 대목은 사이버보안 능력을 “의도적으로 훈련하지 않았다”고 못 박은 것이다. 실제로 브라우저 취약점 공격 도구를 만들게 시켜봤더니 완성하지 못했다는 테스트 결과까지 발표문에 실었다.
그리고 조용히 지나가기 쉬운 것 하나. tokenizer가 바뀌었다. tokenizer는 모델이 텍스트를 토큰(과금의 기본 단위)으로 쪼개는 방식인데, 이게 바뀌면서 같은 문장을 넣어도 이전보다 약 1.0–1.35배 많은 토큰으로 계산될 수 있다. 명목 단가와 실제 청구액이 다르게 움직일 수 있다는 뜻이다.
왜 중요한가
프론티어 성능의 유통기한이 짧아지고 있다. 최상위 등급에 근접하는 성능이 중간 등급 가격으로 내려오는 주기가 눈에 띄게 빨라졌다. 실무 감각으로 말하면 이렇다 — 작년에 “이 작업은 Opus급 아니면 안 된다”고 결론 냈던 목록이 있다면, 그 목록은 이제 낡았다. 모델 선택 기준은 한 번 정하고 끝나는 게 아니라 분기마다 다시 검증해야 하는 대상이 됐다.
무료 플랜 기본 모델의 교체는 벤치마크 순위보다 파급이 크다. 처음 AI를 써보는 사람이 만나는 첫 모델의 수준이 그 사람의 “AI는 이 정도구나”라는 인상을 결정한다. 그 기본값이 한 세대 올라갔다. 주변에 “써봤는데 별로던데”라고 했던 사람이 있다면, 그 판단의 근거가 이번 주에 갱신됐다.
“안 만든 능력”을 문서로 공개하는 흐름. 사이버보안 능력을 뺐다는 사실과 그 검증 결과를 발표문에 그대로 실었다. 무엇을 할 수 있는지의 경쟁만큼, 무엇을 안 하는지를 투명하게 밝히는 것이 배포 신뢰의 조건이 되어가고 있다.
My Take
나는 이 발표를 “모델 배분을 다시 짜라”는 신호로 읽었다. 구체적으로 해볼 만한 것 세 가지.
첫째, 비싼 모델에 맡기던 작업 3개를 골라 같은 프롬프트로 Sonnet 5에 돌려보자. 코드 리뷰, 긴 문서 요약, 복잡한 분석 — 평소 “이건 최상위 모델감”이라고 분류했던 것들이다. 결과가 눈에 띄게 다르지 않다면 그 작업은 한 등급 내려도 된다. 도입가가 유지되는 8월 31일까지가 이 실험을 싸게 돌릴 수 있는 기간이다.
둘째, 비교는 단가표가 아니라 청구서로. tokenizer 변경 때문에 같은 입력도 토큰 수가 최대 1.35배까지 늘 수 있다. $3라는 명목 단가만 보고 “싸졌네”라고 판단하면 틀릴 수 있다. API를 쓴다면 같은 작업의 실제 토큰 수를 전후로 찍어보고, 구독 플랜이라면 usage limit이 닳는 속도를 체감으로라도 비교해 보는 게 정확하다.
셋째, 무료 플랜 사용자라면 유료 결제를 고민하기 전에 지금 기본 모델로 어디까지 되는지부터 확인하자. 기본값이 좋아졌다는 건, 돈을 쓰기 전에 공짜로 검증할 수 있는 범위가 넓어졌다는 뜻이기도 하다.
마지막으로 한 번 더 — “Opus 4.8에 근접”은 Anthropic의 자체 평가다. 내 작업에서도 성립하는지는 내 작업으로만 확인할 수 있다. 그리고 그 확인 과정 자체가, 모델이 바뀔 때마다 흔들리지 않는 자기만의 판단 기준을 만드는 훈련이 된다.