왜 지금 HBM을 이해해야 하는가
2023년 이후 반도체 업계에서 가장 많이 언급되는 단어를 하나만 꼽으라면 단연 HBM(High Bandwidth Memory, 고대역폭메모리)이다. 엔비디아의 AI 가속기 한 장에는 HBM이 여러 개 얹혀 있고, 이 HBM을 누가 얼마나 빨리, 얼마나 많이 공급하느냐가 SK하이닉스·삼성전자·마이크론이라는 세 회사의 실적을 좌우하는 핵심 변수가 됐다.
그런데 정작 “HBM이 정확히 무엇인가”라는 질문에 답하려면 반도체·메모리에 대한 기초 지식이 먼저 필요하다. 트랜지스터가 뭔지, D램이 왜 계속 전기를 먹는지, ‘대역폭’이 정확히 뭘 의미하는지를 모르면 HBM에 대한 뉴스 기사를 읽어도 절반만 이해하고 넘어가게 된다.
이 글은 반도체를 처음 공부하는 사람의 눈높이에서, 가장 기초적인 개념부터 시작해 HBM의 물리적 구조와 제조공정, 그리고 세대별 진화 과정까지 단계적으로 쌓아 올린다. 중간에 어떤 개념도 “당연히 알겠지”라고 건너뛰지 않는다.
1부. 반도체란 무엇인가
1-1. 반도체의 정의 — 전기가 통하기도, 안 통하기도 하는 물질
반도체(semiconductor)는 전기가 잘 통하는 도체(구리·금 등)와 전기가 거의 통하지 않는 절연체(유리·고무 등)의 중간 성질을 가진 물질이다. 대표적으로 실리콘(Si)이 반도체 물질로 쓰인다. 반도체의 진짜 쓸모는 여기서 나온다 — 순수한 실리콘에 특정 불순물을 아주 소량 섞으면(이를 ‘도핑(doping)‘이라 한다), 전기가 통하는 정도를 인위적으로 조절할 수 있다.
이 조절 가능성 덕분에 반도체로 “전류를 흐르게 할지 말지”를 스위치처럼 제어하는 소자를 만들 수 있다. 이 스위치 역할을 하는 가장 기본적인 부품이 **트랜지스터(transistor)**다.
1-2. 트랜지스터 — 모든 반도체 칩의 최소 단위
트랜지스터는 전압을 걸었을 때 전류가 흐르거나 흐르지 않도록 제어하는 스위치다. 이 스위치가 켜진 상태를 디지털 신호 ‘1’로, 꺼진 상태를 ‘0’으로 대응시키면, 트랜지스터의 조합만으로 0과 1로 이루어진 모든 디지털 연산과 저장이 가능해진다. 현대 반도체 칩 하나에는 이런 트랜지스터가 수십억 개에서 많게는 수백억 개까지 들어간다.
반도체 산업 전체를 이해하는 첫 번째 열쇠는 이것이다 — “트랜지스터를 얼마나 작게, 얼마나 많이, 얼마나 빠르게 만들 수 있는가”가 이 산업의 경쟁력을 결정한다는 사실이다.
인텔의 공동창업자 고든 무어는 1965년 “반도체 집적회로에 들어가는 트랜지스터 수가 약 2년마다 두 배로 늘어난다”는 경험적 관찰을 내놓았다. 이를 **무어의 법칙(Moore’s Law)**이라 부른다. 법칙이라기보다는 업계가 지켜온 목표에 가까웠지만, 지난 수십 년간 반도체 미세공정 발전의 방향을 상징하는 표현으로 자리 잡았다.
1-3. 로직 반도체 vs 메모리 반도체 — 역할의 분리
트랜지스터로 만드는 반도체 칩은 크게 두 종류로 나뉜다.
- 로직 반도체(Logic semiconductor): 연산을 수행하는 칩. CPU(중앙처리장치), GPU(그래픽처리장치), AP(모바일 애플리케이션 프로세서) 등이 여기 속한다. “생각하는” 역할을 한다.
- 메모리 반도체(Memory semiconductor): 데이터를 저장하는 칩. D램(DRAM), 낸드플래시(NAND Flash) 등이 여기 속한다. “기억하는” 역할을 한다.
삼성전자·SK하이닉스는 메모리 반도체 시장에서, 엔비디아·인텔·AMD·TSMC는 로직 반도체(설계 또는 파운드리) 시장에서 강자로 꼽힌다. HBM은 이 중 메모리 반도체 카테고리에 속하지만, 뒤에서 살펴볼 것처럼 로직 다이와 물리적으로 한 몸처럼 결합해 쓰인다는 점에서 두 세계를 잇는 제품이기도 하다.
2부. 메모리 반도체의 두 축 — D램과 낸드플래시
2-1. 휘발성 메모리와 비휘발성 메모리
메모리 반도체는 전원이 꺼졌을 때 데이터가 사라지는지 여부에 따라 나뉜다.
- 휘발성 메모리(Volatile memory): 전원이 꺼지면 저장된 데이터가 사라진다. 대표 사례가 **D램(DRAM, Dynamic Random Access Memory)**이다.
- 비휘발성 메모리(Non-volatile memory): 전원이 꺼져도 데이터가 유지된다. 대표 사례가 **낸드플래시(NAND Flash)**이며, 이를 여러 개 묶어 만든 저장장치가 SSD(Solid State Drive)다.
컴퓨터·스마트폰·서버 어디서든 “메인 메모리(RAM)“라고 부르는 부품은 대부분 D램이다. HBM 역시 본질적으로는 D램을 쌓아 올린 것이다 — 즉 HBM을 이해하려면 먼저 D램을 이해해야 한다.
2-2. D램의 작동 원리 — 1개의 트랜지스터, 1개의 축전기
D램의 저장 단위(셀, cell) 하나는 트랜지스터 1개와 축전기(capacitor) 1개로 구성된다. 이를 1T1C(1-Transistor 1-Capacitor) 구조라 부른다.
- 축전기: 전하를 저장하는 부품이다. 전하가 차 있으면 디지털 값 ‘1’, 비어 있으면 ‘0’으로 읽는다.
- 트랜지스터: 이 축전기에 접근할지 말지를 결정하는 스위치 역할을 한다. 데이터를 읽거나 쓸 때만 트랜지스터를 열어 축전기와 연결한다.
문제는 이 축전기가 시간이 지나면 전하가 자연스럽게 새어나간다는 점이다(누설전류). 축전기에 저장된 전하는 길어야 수십 밀리초(ms) 안에 사라져 버린다. 그래서 D램은 데이터가 사라지기 전에 저장된 값을 다시 읽어서 같은 값으로 재기록하는 작업을 끊임없이 반복해야 한다. 이 작업을 **리프레시(refresh)**라고 부르며, 보통 수십 밀리초에 한 번씩 칩 내부에서 자동으로 수행된다. D램이라는 이름의 ‘Dynamic(동적)‘이 바로 이 끊임없는 재충전 동작에서 나온 말이다.
리프레시는 D램 전력 소비의 상당 부분(추정치로 전체 소비 전력의 10% 이상)을 차지한다. D램이 SSD보다 훨씬 빠르지만 전원이 꺼지면 데이터가 사라지는 ‘휘발성’을 갖는 이유, 그리고 계속 전력을 소모하는 이유가 모두 이 1T1C 구조 하나에서 설명된다.
2-3. DDR — D램을 컴퓨터 시스템에 연결하는 표준 규격
D램 칩 자체는 여러 회사(삼성전자·SK하이닉스·마이크론 등)가 만들지만, 이 칩이 컴퓨터의 다른 부품과 호환되게 작동하려면 공통 규격이 필요하다. 이 규격을 정하는 국제 표준화 기구가 **JEDEC(Joint Electron Device Engineering Council)**이다. 우리가 흔히 듣는 DDR4, DDR5 같은 이름이 JEDEC이 정한 표준 D램 규격의 이름이다. DDR(Double Data Rate)은 한 번의 클럭 신호에서 데이터를 두 번 전송해 속도를 높인 방식을 뜻한다.
HBM 역시 JEDEC이 표준을 정한다. 다만 HBM은 DDR 계열과는 완전히 다른 물리적 접근 방식을 취하는데, 이 차이가 이 글의 핵심 주제다.
3부. 메모리 월(Memory Wall) — HBM은 왜 등장했는가
3-1. 폰노이만 구조와 병목 지점
현대 컴퓨터 대부분은 **폰노이만 구조(Von Neumann architecture)**를 따른다. 이 구조에서는 연산을 담당하는 프로세서(CPU·GPU)와 데이터를 저장하는 메모리가 물리적으로 분리돼 있고, 둘 사이를 좁은 통로(버스, bus)로 연결한다. 프로세서가 아무리 빨라도 이 통로를 통해 데이터를 주고받는 속도가 느리면, 프로세서는 데이터가 도착할 때까지 그냥 기다려야 한다.
지난 수십 년간 프로세서의 연산 속도는 무어의 법칙을 따라 기하급수적으로 빨라졌지만, 메모리와 프로세서를 잇는 통로의 대역폭(bandwidth, 단위 시간당 전송 가능한 데이터양)은 그만큼 빠르게 늘지 못했다. 이 격차를 **메모리 월(Memory Wall)**이라 부른다 — “프로세서 앞을 가로막는 메모리라는 벽”이라는 뜻이다.
3-2. AI 시대에 메모리 월이 특히 심각해진 이유
이 문제는 AI, 그중에서도 거대언어모델(LLM) 학습·추론이 본격화되면서 훨씬 심각해졌다. LLM은 파라미터(모델이 학습한 가중치 값) 수가 수십억에서 수천억 개에 달하며, 이 파라미터를 GPU 코어로 끊임없이 실어 날라야 연산이 진행된다. GPU의 연산 능력(코어 수·클럭 속도)은 계속 늘고 있는데, 메모리에서 데이터를 실어 나르는 속도가 이를 따라가지 못하면 비싼 GPU 코어가 데이터를 기다리며 놀게 된다 — 이는 곧 AI 인프라 투자의 낭비로 이어진다.
기존 D램(DDR 계열)이나 그래픽 카드용 GDDR 메모리로는 이 요구를 감당하기 어려웠다. 여기서 나온 해법이 “메모리를 옆으로 늘어놓지 말고, 위로 쌓아서 대역폭 자체를 넓히자”는 접근이었다. 이것이 HBM의 출발점이다.
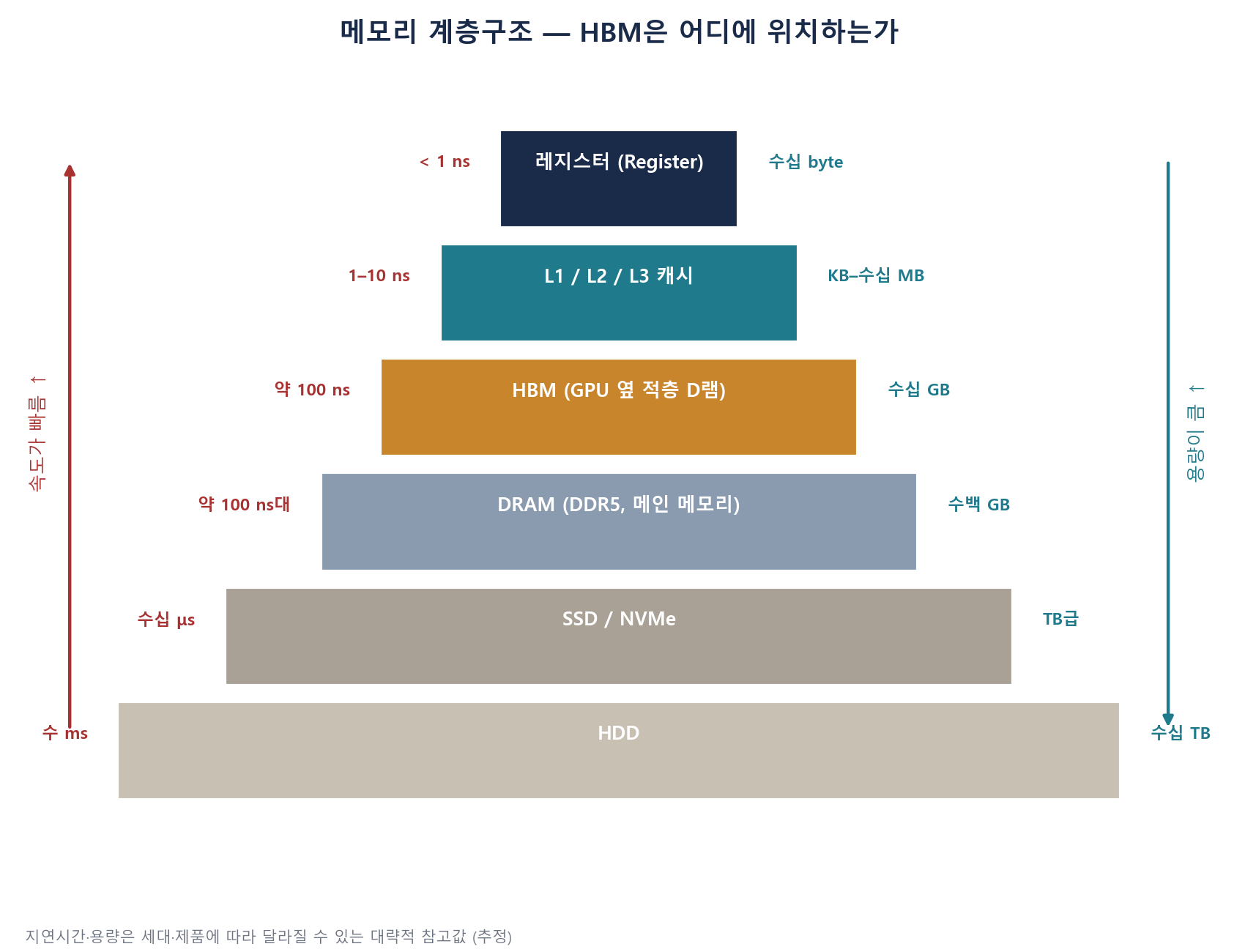
컴퓨터 시스템에는 여러 층의 메모리가 존재한다. 프로세서에 가까울수록(위쪽) 빠르지만 용량이 작고, 멀어질수록(아래쪽) 느리지만 용량이 크다. HBM은 이 계층에서 ‘프로세서 바로 옆에 붙은, 일반 D램보다 훨씬 빠른 메모리’ 자리를 차지한다.
4부. HBM이란 무엇인가 — 정의와 기존 메모리와의 차이
4-1. HBM의 핵심 아이디어 — “옆으로 넓히지 말고 위로 쌓는다”
HBM(High Bandwidth Memory)은 여러 개의 D램 칩을 수직으로 쌓아 올리고, 이를 관통하는 미세한 구멍으로 층 사이를 전기적으로 연결한 3차원 적층 메모리다. 기존 D램이 하나의 칩을 평면(2D)으로 배치해 배선을 연결했다면, HBM은 칩을 여러 층 쌓아(3D) 배선 하나하나를 수직으로 짧게 연결한다.
이 방식의 장점은 두 가지다.
- 대역폭 확대: 배선의 폭(bus width)을 기존 D램보다 훨씬 넓게 만들 수 있다. HBM은 스택 하나당 1,024비트 또는 2,048비트 폭의 통로를 갖는데, 이는 일반 DDR5(64비트 안팎)보다 수십 배 넓다.
- 전력 효율: 배선 길이가 짧아지면 신호를 보내는 데 드는 전력이 줄어든다. 같은 데이터를 옮기는 데 더 적은 전력을 쓴다는 뜻이다.
4-2. HBM vs GDDR — 무엇이 다른가
그래픽카드에는 전통적으로 GDDR(Graphics Double Data Rate) 메모리가 쓰여왔다. GDDR과 HBM은 둘 다 “그래픽·연산용으로 최적화된 고속 메모리”라는 공통점이 있지만 접근 방식이 다르다.
| 구분 | GDDR | HBM |
|---|---|---|
| 구조 | 평면(2D), 개별 칩을 PCB에 배치 | 수직 적층(3D), 여러 칩을 하나의 스택으로 결합 |
| 배선 폭 | 좁음(칩당 32비트 안팎) | 매우 넓음(스택당 1,024–2,048비트) |
| 배치 위치 | 그래픽카드 기판 위, GPU와 다소 떨어져 배치 | GPU 바로 옆, 실리콘 인터포저 위에 근접 배치 |
| 전력 효율 | 상대적으로 낮음 | 상대적으로 높음 |
| 제조 난도·비용 | 낮음 | 매우 높음(TSV·패키징 공정 필요) |
즉 GDDR은 “익숙한 방식으로 적당히 빠르게”, HBM은 “제조가 훨씬 까다롭지만 압도적으로 빠르게”를 택한 결과물이다. AI 가속기처럼 극한의 대역폭이 필요한 곳에는 HBM이, 일반 그래픽카드처럼 비용 효율이 더 중요한 곳에는 여전히 GDDR이 쓰인다.
5부. HBM의 물리적 구조 — TSV와 패키징
5-1. 스택을 이루는 두 종류의 다이
HBM 하나는 여러 개의 얇은 반도체 조각(다이, die)을 쌓아 만든다. 이 다이는 역할에 따라 두 종류로 나뉜다.
- 코어 다이(Core die): 실제 데이터를 저장하는 D램 다이. 여러 층 쌓여 있다.
- 베이스 다이(Base die): 스택의 맨 아래에 위치하며, 코어 다이들을 제어하는 로직 회로와 외부(GPU·인터포저)로 신호를 주고받는 인터페이스 회로(PHY)가 들어 있다. 코어 다이들의 ‘관리자’ 역할을 한다.
5-2. TSV — 다이와 다이를 수직으로 잇는 통로
이렇게 쌓인 다이들을 서로 전기적으로 연결하려면 층을 관통하는 통로가 필요하다. 이 통로가 **TSV(Through Silicon Via, 실리콘관통전극)**다. TSV는 실리콘 다이에 아주 미세한 구멍(지름 약 5–10마이크로미터, 머리카락 굵기의 10분의 1 수준)을 뚫고 그 안을 구리로 채워 만든 수직 전극이다.
기존 반도체 패키징에서는 칩과 칩을 옆에서 가는 금선(와이어)으로 연결하는 와이어본딩 방식이 일반적이었다. TSV는 이 연결을 옆이 아니라 다이 내부를 관통해 수직으로 처리한다는 점에서 근본적으로 다르다. 신호가 지나가는 길이가 짧아지므로 신호 지연(latency)이 줄고, 배선을 훨씬 촘촘하게 배치할 수 있어 앞서 말한 넓은 배선 폭(1,024–2,048비트)이 물리적으로 가능해진다.
5-3. 인터포저 — GPU와 HBM을 잇는 실리콘 다리
HBM 스택은 그 자체로는 GPU와 직접 연결되지 않는다. 둘 사이에는 **실리콘 인터포저(Silicon Interposer)**라는 얇은 실리콘 판이 놓인다. 인터포저는 표면에 매우 미세한 배선을 새길 수 있는 실리콘 재질이라, 일반 PCB(인쇄회로기판)로는 구현할 수 없는 수천 개 단위의 촘촘한 배선을 GPU와 HBM 사이에 깔 수 있다.
정리하면 HBM 패키지는 아래에서 위로 다음과 같은 순서로 쌓인다.
패키지 기판(Package Substrate) → 실리콘 인터포저(Si Interposer) → (좌) GPU/로직 다이, (우) HBM 스택(베이스 다이 + 코어 다이 여러 층, TSV로 관통 연결)
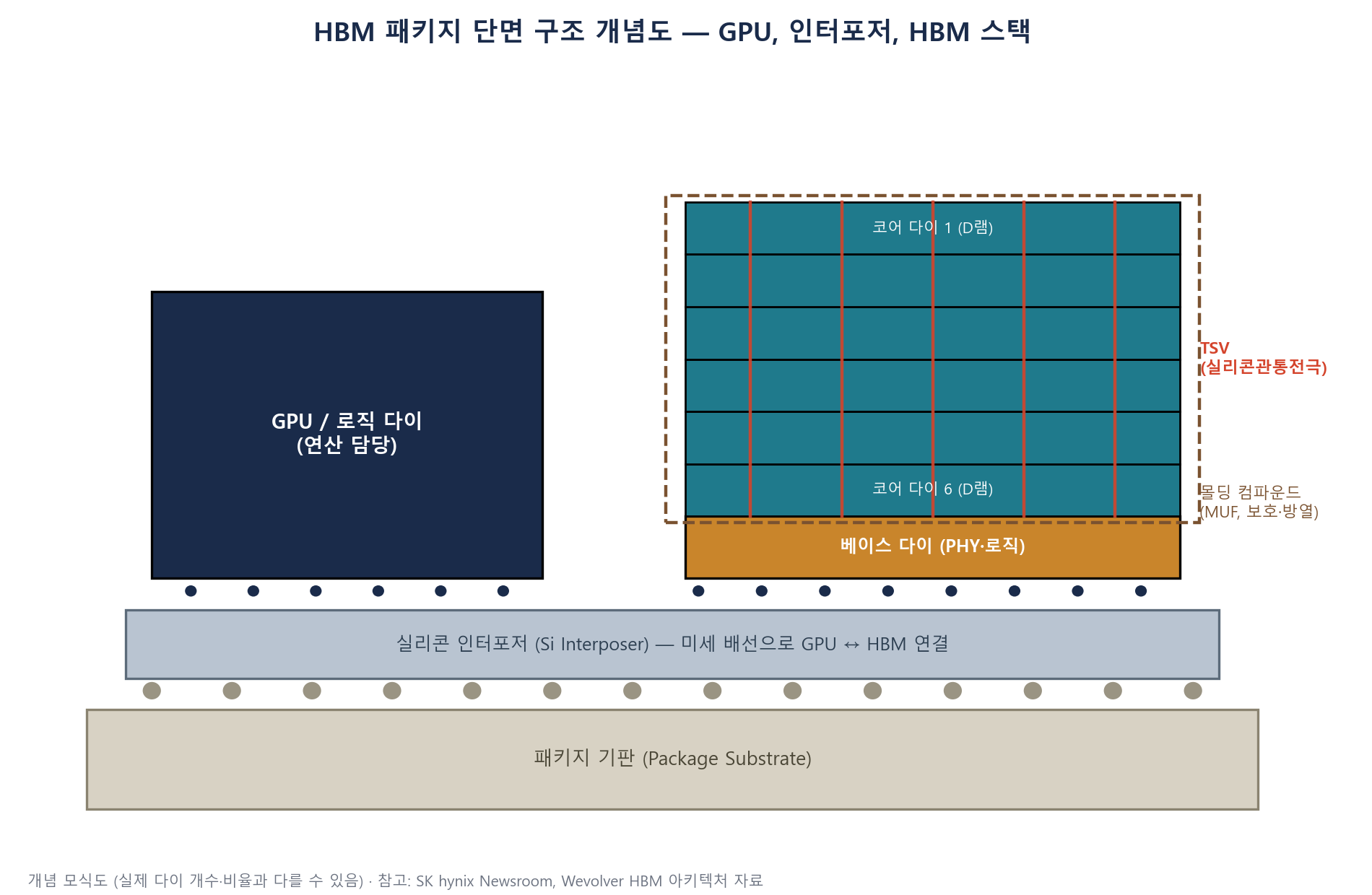
GPU(로직 다이)와 HBM 스택은 같은 인터포저 위에 나란히 놓여 짧은 거리로 연결된다. HBM 스택 내부에서는 TSV(붉은 선)가 코어 다이들을 수직으로 관통하며, 스택 전체는 몰딩 컴파운드로 감싸 보호·방열한다.
이렇게 로직 칩과 메모리 칩을 하나의 패키지 안에, 하나의 인터포저 위에 나란히 배치하는 방식을 2.5D 패키징이라 부른다(완전히 하나의 칩으로 합친 것은 아니지만 평면 배치보다는 훨씬 밀착돼 있다는 뜻). TSMC의 CoWoS(Chip on Wafer on Substrate)가 이 2.5D 패키징을 수행하는 대표적인 공정으로, AI 가속기 생산에서 GPU와 HBM을 하나로 묶는 핵심 병목 공정으로 자주 언급된다.
6부. HBM 제조공정 — 다이를 어떻게 쌓고 붙이는가
TSV로 구멍을 뚫고 다이를 얇게 가공(웨이퍼 씬닝, wafer thinning)한 뒤에는, 이 다이들을 실제로 겹겹이 쌓아 붙이는 접합(bonding) 공정이 필요하다. 크게 두 가지 방식이 업계에서 쓰인다.
6-1. TC-NCF 방식
TC-NCF(Thermal Compression - Non-Conductive Film)는 다이와 다이 사이에 비전도성 필름(NCF)을 끼운 뒤, 열과 압력을 가해(열압착) 한 층씩 순서대로 접합하는 방식이다. 한 층 붙이고 열압착, 다시 한 층 붙이고 열압착을 반복하는 구조라 다이 수가 많아질수록 공정 시간이 길어지는 경향이 있다.
6-2. MR-MUF 방식
MR-MUF(Mass Reflow - Molded Underfill)는 접근이 다르다. 먼저 다이들을 솔더범프(미세한 금속 돌기)로 정렬해 쌓은 뒤, 열을 가해 범프를 한 번에 녹여 붙이고(리플로우), 그다음 다이 사이 빈틈을 액체 상태의 에폭시 몰딩 컴파운드(EMC)로 한꺼번에 채워 굳히는 방식이다. SK하이닉스가 이 공정을 도입해 발전시킨 것으로 알려져 있다.
MR-MUF의 장점은 다이 사이 빈 공간을 채우는 몰딩 컴파운드가 발열을 분산시키는 방열재 역할도 겸한다는 점이다. 업계 자료에 따르면 SK하이닉스의 개선된 MR-MUF 공정은 기존 대비 열저항을 약 17% 낮추고, 16단 적층까지 안정적으로 지원하며, 제조 시간을 약 50% 단축하는 것으로 알려져 있다(회사 발표 기준, 세부 수치는 세대·공정 조건에 따라 달라질 수 있음).
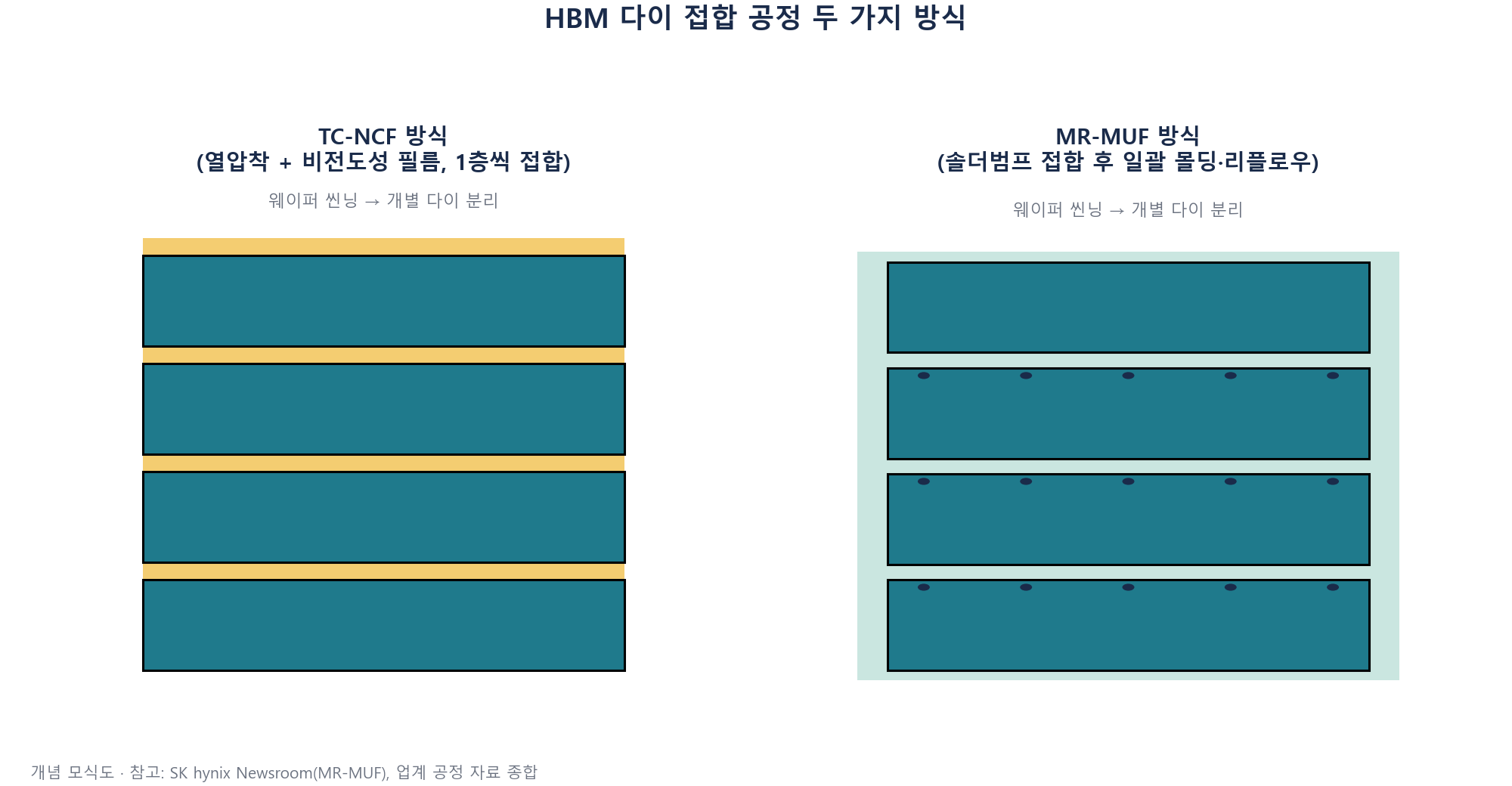
TC-NCF는 필름을 끼워 한 층씩 순서대로 접합하고, MR-MUF는 범프로 먼저 쌓은 뒤 몰딩 컴파운드를 한 번에 채워 굳힌다. 다이가 많아질수록(고단 적층) 접합 방식의 선택이 수율과 방열 성능에 미치는 영향이 커진다.
6-3. 왜 이 공정이 어려운가 — 수율의 문제
HBM 제조의 가장 큰 난제는 **수율(yield)**이다. 스택 하나에 다이가 8층, 12층, 16층으로 늘어날수록 TSV 정렬 오차, 범프 접합 불량, 열에 의한 다이 휘어짐 등 실패 요인이 층마다 누적된다. 게다가 정상적으로 제조된 다이(good die)라 해도, 이를 여러 층 쌓았을 때 단 하나의 다이라도 불량이면 스택 전체를 버려야 한다 — 이를 ‘양품 다이를 쌓았는데 불량 스택이 나오는 문제(known-good-die 문제)‘라 부른다. 층수가 늘어날수록 이 문제는 기하급수적으로 까다로워진다.
7부. HBM 세대별 진화 — HBM1부터 HBM4까지
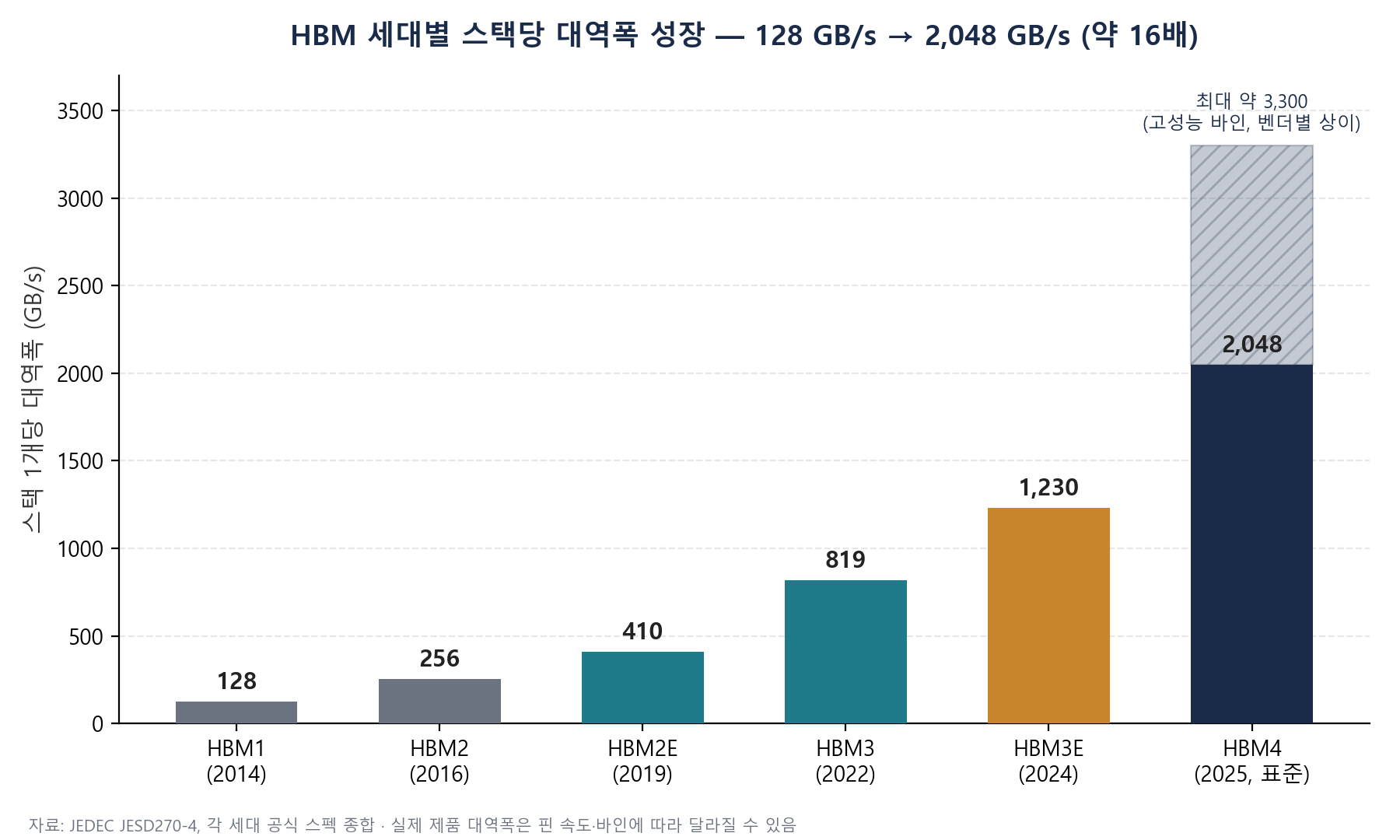
스택 1개당 대역폭은 HBM1(2014년, 128GB/s)에서 HBM4 표준(2025년, 2,048GB/s)까지 약 11년간 16배 늘었다. 벤더가 표준보다 높은 핀 속도를 적용하는 고성능 바인에서는 이보다 더 높은 대역폭도 보고된다.
| 세대 | 발표(양산) 시기 | 인터페이스 폭 | 스택당 대역폭(표준 기준) | 특징 |
|---|---|---|---|---|
| HBM1 | 2014년 | 1,024비트 | 약 128 GB/s | 최초의 JEDEC 표준 3D 적층 D램 |
| HBM2 | 2016년 | 1,024비트 | 약 256 GB/s | 스택당 용량 확대(4–8단) |
| HBM2E | 2019년 | 1,024비트 | 약 410 GB/s | 핀 속도 개선, 용량 16GB까지 확대 |
| HBM3 | 2022년 | 1,024비트 | 약 819 GB/s | 채널 수 확대(16채널), AI 가속기 채택 본격화 |
| HBM3E | 2024년 | 1,024비트 | 약 1,230 GB/s(최대 1.33TB/s) | HBM3 대비 핀 속도 대폭 향상 |
| HBM4 | 2025년(표준 확정) | 2,048비트(폭 2배) | 약 2,048 GB/s | 채널 수 2배(32채널), 최대 용량 64GB |
이 표에서 가장 눈에 띄는 변화는 HBM4에서 인터페이스 폭이 1,024비트에서 2,048비트로 두 배 늘었다는 점이다. 이전 세대들이 주로 ‘핀 하나가 처리하는 속도(핀 속도)‘를 높이는 방식으로 대역폭을 늘려왔다면, HBM4는 여기에 더해 ‘통로 자체의 개수’를 늘리는 방향으로 전환했다. JEDEC은 2025년 4월 이 표준을 JESD270-4라는 문서 번호로 공식 확정했다.
실제 시장에서 유통되는 HBM4 제품은 표준 스펙(초당 8기가비트 핀 속도 기준 2,048 GB/s)보다 더 높은 핀 속도(약 11.7–13 Gbps)를 적용한 ‘고성능 바인’으로 공급되는 경우가 많아, 스택당 최대 약 3,300 GB/s(3.3TB/s)까지 보고되기도 한다. 다만 이는 벤더·제품별로 편차가 크므로 “표준 스펙”과 “실제 최고 성능 제품”을 구분해서 이해할 필요가 있다.
7-1. 채널이란 무엇인가
표에 나온 ‘채널(channel)‘은 HBM 스택 내부에서 독립적으로 데이터를 읽고 쓸 수 있는 통로의 단위를 말한다. 채널 수가 많을수록 여러 데이터 요청을 동시에 병렬로 처리할 수 있어 실질적인 처리 효율이 올라간다. HBM4는 기존 16채널에서 32채널로 늘리면서, 채널 하나를 다시 2개의 ‘가상채널(pseudo-channel)‘로 세분화하는 방식도 함께 적용해 총 64개의 유사-독립 처리 단위를 갖는다.
7-2. 앞으로의 방향 — 커스텀 베이스다이와 HBM4E
HBM4에서 나타난 또 하나의 중요한 변화는 베이스 다이의 커스터마이징이다. 기존에는 메모리 제조사(삼성전자·SK하이닉스·마이크론)가 베이스 다이까지 표준 규격대로 만들었지만, HBM4부터는 GPU 제조사(예: 엔비디아)가 요구하는 로직 회로를 베이스 다이에 맞춤 설계해 넣는 방식이 논의되고 있다. 이 경우 파운드리(TSMC 등)의 로직 공정 기술이 HBM 제조에 결합되는 셈이라, 메모리 회사와 파운드리 간의 협업 구조가 새롭게 요구된다.
한편 차세대 규격으로 언급되는 HBM4E는 핀 속도를 약 16 Gbps까지 끌어올려 스택당 약 4.1 TB/s 대역폭을 목표로 하는 것으로 알려져 있다. 다만 이는 아직 로드맵 단계의 목표치이며, JEDEC의 공식 표준으로 확정된 사안은 아니라는 점을 밝혀둔다(미확정). 2025년 12월에는 JEDEC이 핀 수를 줄이면서도 HBM4 수준의 처리량을 내는 ‘SPHBM4’라는 별도 표준을 준비 중이라는 소식도 전해졌는데, 이는 패키징 복잡도를 낮추려는 시도로 해석할 수 있다(진행 중인 논의로, 세부 내용은 표준 확정 후 달라질 수 있음).
8부. 왜 HBM은 이렇게 어렵고 비싼가 — 산업적 함의
지금까지 살펴본 내용을 종합하면, HBM이 왜 일반 D램보다 훨씬 만들기 어렵고 비싼지가 자연스럽게 설명된다.
- 공정 단계가 훨씬 많다: 일반 D램은 다이 하나를 만들면 끝이지만, HBM은 다이를 만든 뒤 TSV를 뚫고, 얇게 갈아내고(웨이퍼 씬닝), 여러 층을 정밀하게 정렬해 쌓고, 접합하고, 몰딩까지 거쳐야 한다.
- 수율 문제가 누적된다: 스택 층수가 늘어날수록 불량률이 기하급수적으로 늘어날 위험이 있다.
- 발열 관리가 까다롭다: 여러 층을 촘촘히 쌓다 보니 열이 빠져나갈 통로가 좁아, MR-MUF 같은 방열 특화 공정이 필요하다.
- 후공정(패키징) 능력이 곧 병목이다: 완성된 HBM을 GPU와 결합하려면 TSMC의 CoWoS 같은 첨단 패키징 능력이 필요한데, 이 패키징 설비 자체가 전 세계적으로 부족한 상황이 반복돼 왔다. 일부 업계 분석에서는 “진짜 병목은 HBM 자체가 아니라 이를 GPU와 묶는 패키징 공정”이라는 시각도 제기된다.
이 네 가지 난제를 동시에 해결해야 하다 보니, HBM 시장은 소수의 회사만 진입할 수 있는 고진입장벽 시장으로 남아 있다. 실제로 2026년 기준 HBM 공급사는 SK하이닉스·삼성전자·마이크론 세 곳으로 좁혀져 있으며, 이들 사이의 기술 격차가 곧바로 시장 점유율과 수익성의 격차로 이어지는 구조다.
My Take
이 글을 쓰면서 가장 강조하고 싶었던 지점은, HBM을 “그냥 빠른 메모리” 정도로 이해하고 넘어가면 이 기술이 왜 그렇게 큰 산업적 파장을 일으키고 있는지를 놓치게 된다는 것이다. HBM의 본질은 메모리 소자 자체의 혁신이라기보다, “메모리를 쌓아 올리고, 로직 칩 바로 옆에 붙이고, 그 사이를 실리콘 배선으로 잇는” 패키징 방식의 혁신에 가깝다고 생각한다. 그래서 HBM 경쟁력의 핵심 승부처도 D램 셀 설계보다는 TSV 정렬 정밀도, 접합 수율, 방열 성능 같은 공정 기술에 있다.
또 하나 흥미로운 지점은, HBM4에서 나타난 ‘베이스 다이 커스터마이징’ 흐름이다. 지금까지 메모리 회사는 로직 회사와 비교적 독립적으로 자기 영역(메모리)에서만 경쟁해왔는데, 앞으로는 GPU 회사의 요구사항을 반영한 맞춤 설계가 늘어나면서 메모리·로직·파운드리 세 영역의 경계가 점점 흐려질 수 있다고 본다. 이 흐름이 앞으로 소자·공정·패키징 중 어느 연구 분야와 맞닿게 될지를 함께 생각해보면 좋을 것 같다.